Advice for Applying ML/DL (2)
Training 보다 Testing의 결과가 좋지 않을 때, 이 문제를 Bias와 Variance의 문제로 나눌 수 있다.
위의 문제를 Regularization을 통해 해결했었고, 이 문제가 Bias때문에 발생했는지 Variance 때문에 발생했는지 확인할 때 Learning Curve를 사용한다.
이번 시간에는 Bias 와 Variance에 대해 알아보고 위의 과정에 대해 알아보자.

사진에서는 d=2일 경우에 적당하게 튜닝됐다고 할 수 있고 나머지의 경우는 Underfit 혹은 Overfit 상태이다.
여기서 underfit의 경우 High bias가 끼어있다고 표현한다. 이 경우 데이터를 아무리 많이 박아도 문제는 해결되지 않는다. 다음으로 overfit의 경우에는 High variance의 문제를 가지고 있다고 표현한다.
위 그림에서 우리가 원하는 건 가운데의 2차식의 모델이다.
우리가 한 번에 2차식의 모델이라고 맞출 수는 없다. (차원이 커지고 데이터가 많아지면 사람이 직접 모델을 설계하는 건 불가능하기 때문.) 그러니 이 부분에서 CV의 도움을 받아야 한다.

위와 같이 문제를 표현할 수도 있다.
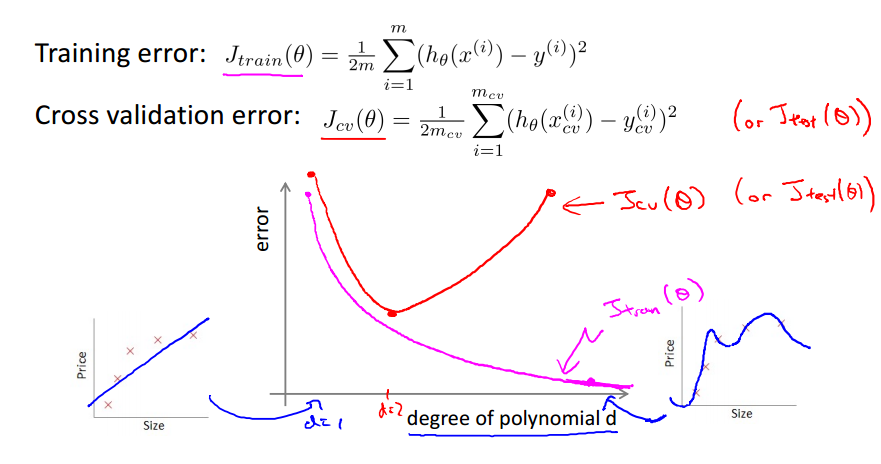
Bias와 Variance를 위와 같이 Error Curve에 대해서도 생각해 볼 수 있다. (x축은 차수)
1차부터 Error Curve를 생각해 봤을 때 차수가 늘어나면 늘어날수록 Training에 대한 에러는 줄어들게 된다.
하지만 그거에 비해 Testing에 대한 에러는 줄어들지 않는다. 어느 순간부터는 급격하게 오류가 증가하게 된다.(Overfitting)

Bias 문제인지 Variance 문제인지 어떻게 확인할 수 있을까?
Testing 에러와 Training 에러 둘 다 높으면 Bias 문제이고 Training 에러는 적지만 Testing에러가 높으면 Variance 문제라고 파악할 수 있다.
어떤 문제인지 파악할 수 있으면 그에 따라 솔루션을 생각할 수 있기 때문에 이 과정은 매우 중요하다.
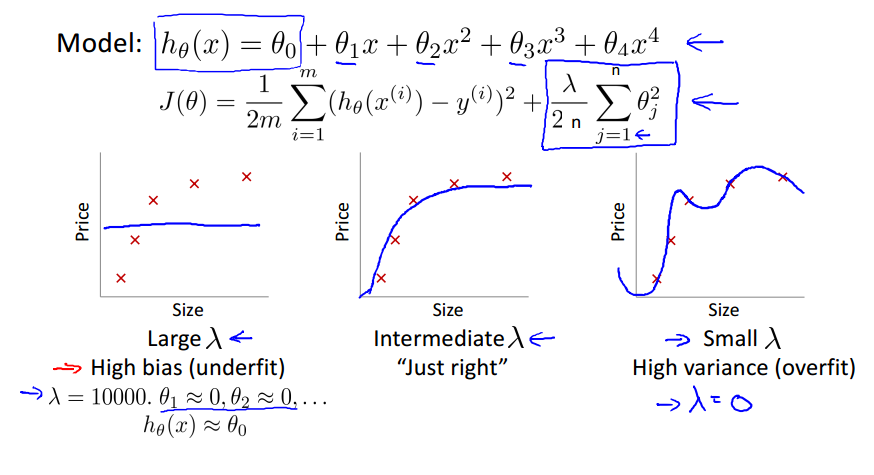
Loss function 등을 이용해 오차를 수정하는 경우를 생각해보자.
위의 식에서 람다값을 조정해서 오차를 수정하게 되는데, 여기서 람다값이 너무 작으면 Overfit문제를 발생시킬 수 있고 너무 크면 Underfit 문제를 발생시킬 수 있다.
우리가 원하는 람다값은 가운데 그래프처럼 적당하게 그래프를 튜닝해주는 값이다.
여기서 람다를 튜닝할 때 CV를 사용할 수 있다. (람다는 Regularization parameter 이다)

h(x)로 하나의 모델이 있고
J(theta)로 Cost function이 있다.
Training / Cross Validation / Test 에 대한 에러 함수는 Cost function과 다름을 잊지 말자.

람다값을 0 부터 10 까지 설정해서 진행했다. 각각의 경우마다 최적의 theta값이 나오게 된다. (theta0 ~ theta4 에 대한 최적의 값이 나온다.)

Cross Validation 곡선에서 접선의 기울기가 0 이 되는 부분에서 람다값을 설정하는 게 합리적이다.
x축을 다항식의 차수로 설정했을 때의 그래프를 y축으로 대칭한 그래프와 비슷하다.
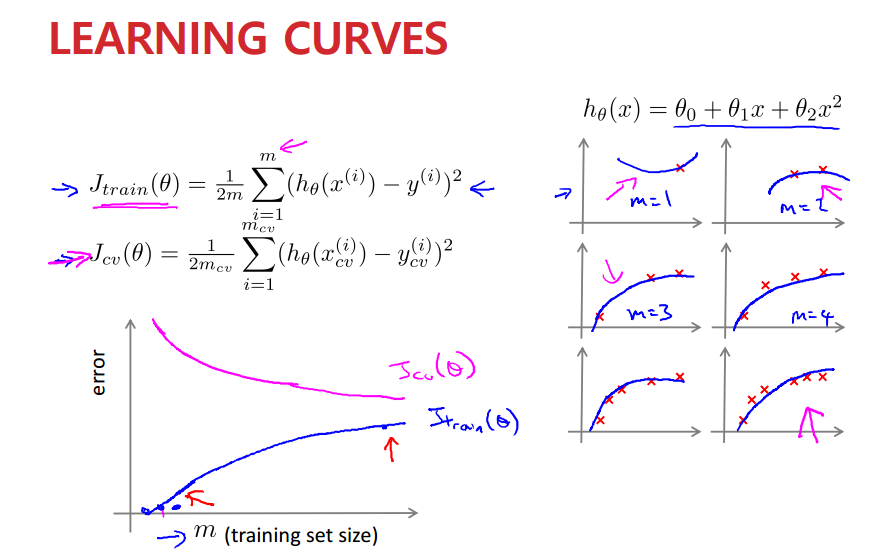
x축을 training set size로 설정하고 Learning Curve에 대해 알아보자.
데이터의 수가 많아질수록 우리가 원하는 이차곡선의 형태가 나타난다.
Training set size가 커질수록 training error는 증가한다. (상단의 오른쪽 그림 참고해서 이해하기. Cumulative)
반면 Cross Validation Error는 감소하는 형태를 보인다.
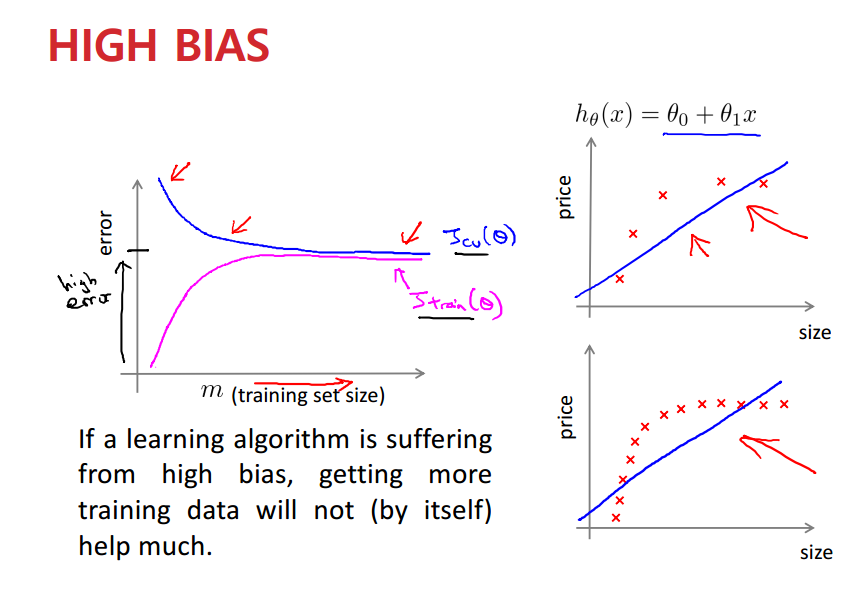
High Bias가 끼어있는 모델에 대해 그래프를 생각해보자.
데이터는 2차 이상을 요구하는 것 처럼 보이고, 1차로는 할 수 있는 게 없어 보인다. (이걸 Bias라고 표현)
여기서 데이터가 많다고 해서 도움이 되지 않는다.
데이터는 복잡한데 모델은 간단하기 때문에, 두 곡선이 수렴하는 부분의 오류가 높게 나올 수 밖에 없다.
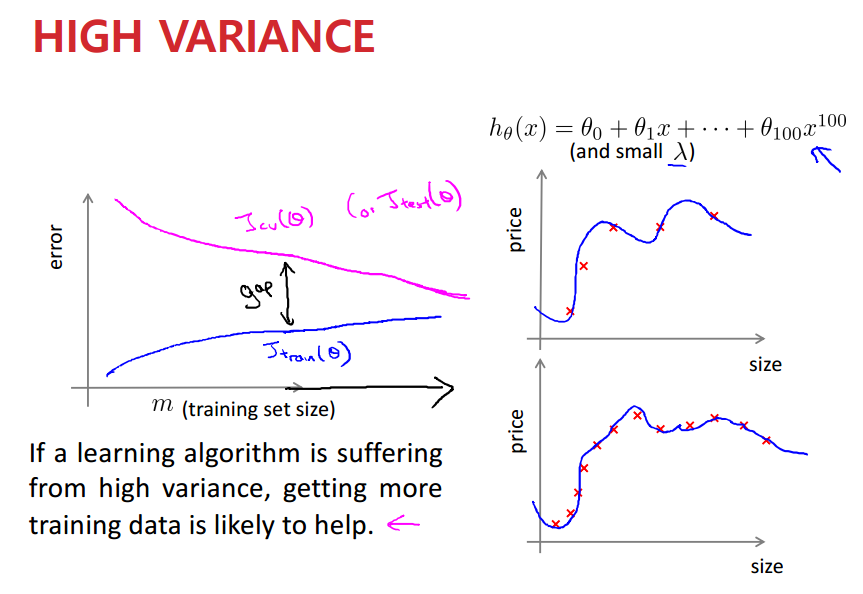
High Variance에서의 그래프이다.
여기서 데이터의 수가 점점 많아지면, 전체적인 형태가 좀 더 개선된다.
이에 따라 두 그래프의 교점에서의 에러도 낮아진다.
즉, High Variance에서는 데이터를 많이 넣는 게 도움이 된다.

즉, Bias와 Variance에 대해서 서로 다른 솔루션이 제공된다.
Traditional Machine Learning에서는 이런 식으로 하고... 그럼 Deep Learning에서는 어떻게 진행할까?
Neural Network를 Regularization 해 보자.
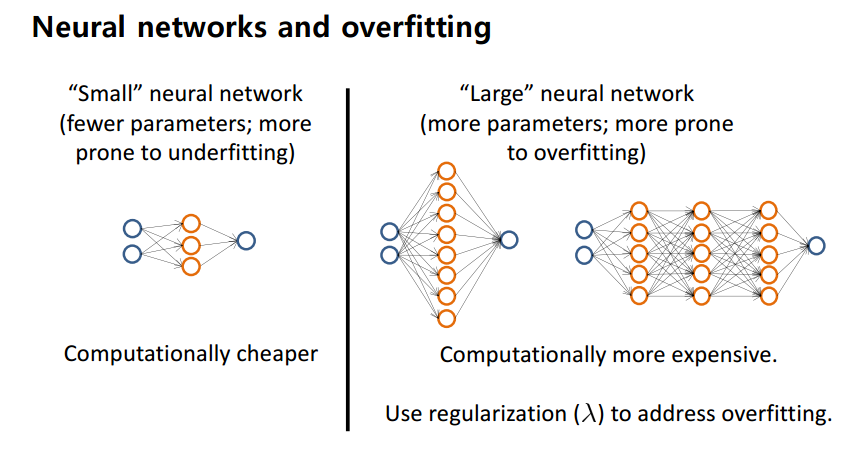
Small neural network에는 작은 매개변수가 있고 underfitting 문제가 발생한다.
반면에 Large에서는 overfitting 문제를 발생할 수 있다.

그러면 어떻게 오류를 예방할 수 있을까?
위와 같이 필요 없는 theta 값들을 없애는 방향으로 overfitting 문제를 예방할 수 있다.
theta값이 0에 근접하면 필요 없다고 생각할 수 있고, 람다를 적당히 튜닝해 없애 줄 수 있다.
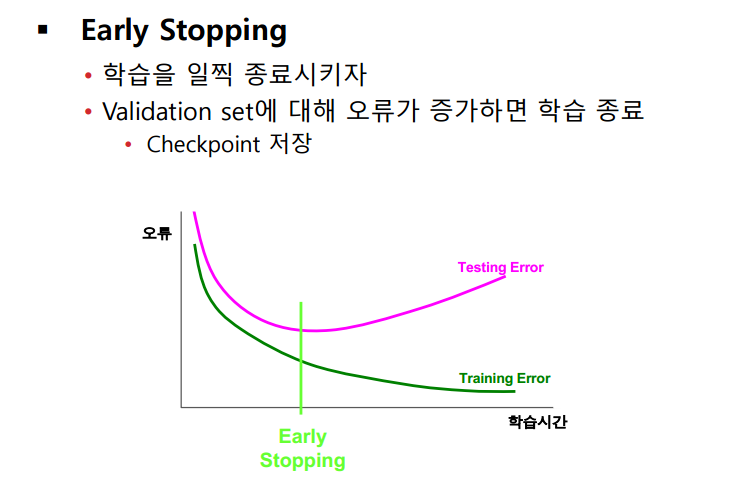
두 번째 방법으로 overfitting 문제가 발생하기 전에 Validation set 에 대해 오류가 증가할 때 학습을 종료하는 방법이 있다.

Training 할 때만 사용한다. 학습 할 때 노드 사이의 연결을 끊어서(끊는 노드는 무작위로 결정) 학습시킨다.
학습을 마무리 한 다음에 노드를 끊지 않은 상태로 testing을 진행한다.
신기하게 이렇게 하면 잘 된다. 요즘은 dropout기술을 default로 집어넣는 추세이다.
이렇게 노드 사이의 연결을 끊으면서 특정 파라미터 W 가 커지는 걸 방지한다.
즉, 어떤 특정한 파라미터에 의존해서 학습을 진행하는 걸 방지할 수 있다. 이로써 각 파라미터들의 의존도를 비슷하게 맞춘다. 이 방법은 Regularization과 상당히 비슷하다.
'Machine Learning > AI Introduction' 카테고리의 다른 글
| Machine Learning - RNN (0) | 2021.12.05 |
|---|---|
| Deep Learning - CNN (0) | 2021.12.05 |
| Advice for Applying ML/DL (1) (0) | 2021.12.04 |
| Deep Learning (4) (0) | 2021.12.03 |
| Deep Learning (3) (0) | 2021.11.18 |