[시스템 프로그래밍] 컴퓨터 시스템과 정보의 표현

컴퓨터 시스템은 소프트웨어와 하드웨어로 구성된다. (시스템 = 소프트웨어 + 하드웨어)
가장 밑바닥에 하드웨어가 위치하고, 운영체제가 하드웨어를 관리해준다.
컴퓨터 시스템이 밑에 있고, 시스템 위에 C, Java 등으로 작성한 응용 프로그램이 올라간다.
BUS / I.O / main memory / cache memory / CPU 등이 하드웨어에 속한다.
BUS
버스는 하드웨어 요소들을 연결하고 데이터를 전송하는 통로 정도로 생각하면 된다. (워드 단위로 전송한다)
CPU
연산장치(ALU), 제어장치 및 레지스터로 구성되어있고 컴퓨터의 두뇌 역할을 한다.
CPU는 클락 펄스마다 명령 주기 (Instruction Cycle) 를 반복한다.
1. 인출 (fetch) : Program Counter에 의거해 명령어를 가져온다.
2. 해독 (decode) : 명령어를 해석해 제어 신호를 생성한다.
3. 실행 (execution) : 가져온 명령어를 실행한다.
4. 결과 저장 (store) : 실행 결과를 저장한다.
첫 번째 클락 펄스에서는 인출을, 그 다음 클락 펄스에서는 해독을... 이렇게 한 사이클을 다 돌고 나면 다시 다른 사이클을 시작한다.
OS
애플리케이션이 하드웨어를 효과적으로 사용할 수 있도록 도와주는 프로그램이다.
여기서 프로그램이라는 단어를 사용했는데, 애플리케이션이 응용 소프트웨어라면 여기서 설명하는 운영체제는 시스템 소프트웨어이다.
운영체제는 프로세스 / 메모리 / I.O장치 / 소프트웨어 자원(ex. vi 에디터) 등을 관리하고, 응용 프로그램들이 하드웨어를 제대로 사용할 수 있도록 도와준다.
즉, 하드웨어를 추상화해서 애플리케이션이 하드웨어가 어떻게 작동하는지에 집중하는 대신, 애플리케이션 자체 기능에 집중할 수 있도록 한다.
컴퓨터의 모든 정보는 비트와 바이트로 저장된다.
1바이트는 8비트로 표현되고, 텍스트는 아스키 표준을 사용해서 표현한다.
모든 정보들은 비트의 모음으로 표현되고, 정보를 바라보는 시각 (컨텍스트) 에 따라 다르게 해석된다.
당신은 Hello World! 를 출력하는 C 프로그램을 작성했고, 누군가가 방금 리눅스 환경에서 gcc -o hello hello.c 명령어를 입력했다.
즉, 컴퓨터 시스템 위에 C 응용 프로그램이 올라왔고 이제 컴퓨터 시스템들이 동작해 응용 프로그램을 실행시킨다.
C 프로그램이 컴파일 되는 과정을 살펴보자.
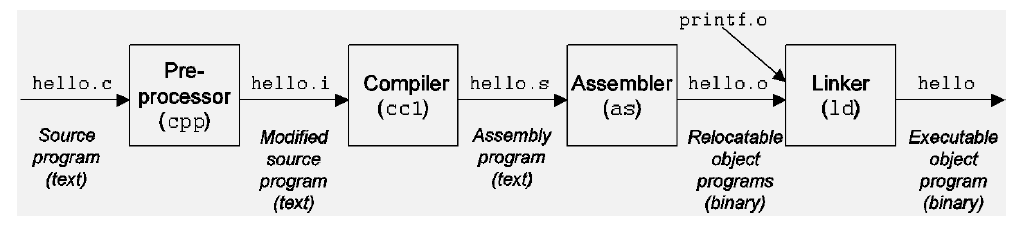
gcc : 컴파일러를 부르는 명령어
-o : hello.c 파일을 읽어서 hello 파일을 만들어내라는 옵션을 준다
먼저 C언어의 전처리기가 동작한다. (preprocessor)
전처리기가 #include #define 등을 처리해 코드에 넣어주고 수정된 텍스트파일인 hello.i 를 만들어낸다.
이제 컴파일러가 돌아간다.
컴파일러가 내부 규칙에 따라 소스코드를 해석하고, 어셈블리 파일인 hello.s 를 만들어낸다.
이제 어셈블러가 작동한다.
어셈블러가 어셈블리 파일을 읽고 CPU가 이해할 수 있는 바이너리 파일인 hello.o 를 만들어낸다.
마지막으로 링커가 작동한다.
사용자가 작성한 hello.o 를 실행하기 위해 필요한 작업들 (이미 컴파일 된 파일들을 hello.c와 연결시켜준다) 을 처리 해 주고, 실행할 수 있는 파일인 hello 가 만들어진다.
힘들게 컴파일 했으니 이제 실행해보자.
누군가가 리눅스 환경에서 ./hello 명령어를 타이핑했다.
여기서 ./ 은 현재 디렉토리이고, hello는 파일 이름이다.
실행되는 과정을 자세히 살펴보자.

여기서 CPU 내부의 PC는 Program Counter 레지스터이고, 메인 메모리의 주소 값을 가지고 있다. (Instruction Pointer라고도 부른다)
PC의 주소가 가지고 있는 메인 메모리의 주소를 통해 메인 메모리에 접근하고, Instruction Cycle을 반복한다.
즉, PC가 가지고 있는 주소를 통해 메모리에 접근하는 작업이 사이클의 시작이 된다.
프로그램이 컴파일 될 때 링커가 메인 메모리의 주소를 얻고, Virtual Machine으로 추상화해서 PC에 가상 주소를 할당해 주는데... 자세한 내용은 운영체제에서 배우고, 일단은 PC는 메인 메모리의 주소를 가지고 있다 정도만 기억하자.
Disk에는 컴파일 후 생성된 hello이름의 실행 파일이 저장돼있다.
사용자가 키보드를 통해 ./hello 명령어를 입력하면, I/O bus를 통해 명령어가 전달되고, I/O bridge를 경유해 CPU에 도착한다.
CPU에서는 위에서 설명한대로 사이클을 돌고 있다.
CPU 레지스터에 잠깐 저장됐다 메인메모리에 사용자가 입력한 ./hello가 저장된다.
이제 엔터를 눌렀다.
컴퓨터는 hello가 실행 파일임을 알고 있다.
Disk에 있는 hello파일을 열고, 파일 내부의 바이너리 코드들을 메인 메모리에 로딩한다.

CPU는 다시 사이클을 돈다.
메인 메모리를 찾아서 로딩된 값들을 가져온다. 값들을 다 읽을 때 까지 사이클을 돈다.
다 읽었으면 사용자에게 실행 결과를 보여준다.
이렇듯, 시스템이 정보를 이동시킬 때는 많은 시간이 소모된다.
또, 메인 메모리처럼 큰 저장장치는 레지스터처럼 작은 저장장치보다 느린 속도를 가진다.
때문에 메인 메모리보다 레지스터를 사용하는 편이 속도 측면에서 합리적이고, 캐시를 도입해서 이 부분을 해결한다.
작고 빠른 캐시 메모리를 사용해 프로세서가 곧 필요하게 될 가능성이 높은 정보를 임시로 저장해서 메인 메모리까지 접근하는 대신 캐시 메모리를 통해 빠르게 정보를 얻을 수 있도록 한다.
트랜지스터는 전압에 따라 전류가 흐름이 결정되는 semi-conductor로 만들어진다. (전류가 흐르거나, 흐르지 않거나)
CPU도 트랜지스터로 만들어지기 때문에, 컴퓨터는 트랜지스터의 두 가지 상태 (전류의 흐름 유무) 를 0과 1로 표현하기 위해 2진수를 사용한다.
본질은 전압이 2.0V / -3.5V 처럼 전류의 세기이다.
전압의 세기에 따라 전류가 흐르거나 흐르지 않게 되는 반도체로 만들어진 트랜지스터, 그리고 그 트랜지스터를 사용해서 만든 CPU.. 이렇게 연결된다.
16진수는 2진수를 4비트씩 묶어서 편하게 사용하기 위해 사용한다.
CPU가 메모리에 접근할 때, 먼저 메모리의 주소를 알아야 한다.
주소의 길이에 따라 한 번에 읽고 쓸 수 있는 메모리의 크기가 결정된다.
32비트 컴퓨터는 주소 범위가 4GB로 제한되고, 64비트 컴퓨터는 0 ~ 2^64 - 1 까지니까.. 핵심은 비트 수가 커질수록 접근할 수 있는 주소의 범위가 넓어지고, 이에 따라 무거운 프로그램을 돌릴 수 있게 되고, 프로그램의 실행 속도가 빨라진다.
여담으로, 64비트 컴퓨터는 메모리를 한 번에 8바이트씩 읽어올 수 있다고 하지만, CPU 설계자에 따라 사용하는 비트 수가 다르다. (48비트를 사용하는 경우도 있다)
그러면 64비트 컴퓨터가 돌릴 수 있는 프로그램은 32비트 컴퓨터도 시간을 좀 많이 쓰면 돌릴 수 있는거 아닌가??
.. 라고 생각할 수 있지만,
반은 맞고 반은 틀리다.
프로그램에 따라서 위의 작업이 가능한 경우가 있고, 불가능한 경우가 있다. (예시로, 인텔은 32비트 컴퓨터가 느리더라도 프로그램을 돌릴 수 있도록 설계했다)
프로그램의 명령어 체계에서도 차이가 있는 경우가 생기기 때문에, "32비트 컴퓨터가 느리더라도 64비트 컴퓨터 전용 애플리케이션을 돌릴 수 있다!" 는 항상 성립하지 않는다.
메모리에 접근할 때 사용되는 단위는 word이다.
워드의 첫 번째 바이트의 위치를 지정하고, 메모리를 읽어 올 때는 컴퓨터에 따라 4바이트 혹은 8바이트씩 끊어서 읽어온다. (컴퓨터가 사용하는 CPU에 따라 워드 단위가 다르다)

컴퓨터에서 데이터를 표시할 때, 타입에 따라 사용하는 비트 수가 다름을 이해하자.
여러 바이트로 이루어진 데이터는 운영체제마다 저장되는 순서도 다르다.
여기 int 타입의 변수 x가 주어진다.
int x = 0x1234567 // 4바이트의 워드이고, x의 주소는 0x100 이다.
여기서 LSB (Least Significant Byte) 는 67 이고, MSB (Most Significant Byte) 는 12 이다.
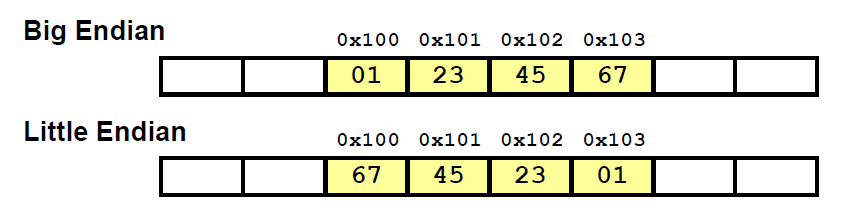
위의 그림에서 볼 수 있듯, 메모리 주소의 단위는 1바이트이고, 16진수로 표현한다.
왜?? 그냥 관례적으로 사용한다.
어쨌든 다시 돌아와서.. Big Endian은 LSB가 최대 주소에 저장되고, Little Endian은 LSB가 최소 주소에 저장된다.
이 때 바이트 단위로 저장됨을 기억하자.
이 두 가지 방식을 Byte Ordering이라고 부른다.
Big Endian 방식으로 데이터를 저장하는 운영체제와 Little Endian 방식으로 데이터를 저장하는 운영체제 간 데이터 교환 시 유의하자.
인텔 기반의 리눅스/윈도우와 IOS 안드로이드는 리틀 엔디안을, Sun Oracle은 빅 엔디안을 사용한다.
'Computer Science > System Programming' 카테고리의 다른 글
| [시스템 프로그래밍] 프로시저 (0) | 2022.10.28 |
|---|---|
| [시스템 프로그래밍] 어셈블리어 - 반복문 (0) | 2022.10.24 |
| [시스템 프로그래밍] 어셈블리어 - 조건문 (0) | 2022.10.23 |
| [시스템 프로그래밍] 어셈블리어 (0) | 2022.10.13 |
| [시스템 프로그래밍] 정수의 산술연산과 실수의 표현 (0) | 2022.09.29 |