[Spring Data JPA] 벌크 연산과 EntityGraph
JPA를 공부할 때 배웠듯, 한 번에 여러 데이터들을 한 번에 수정하는 경우 벌크 연산을 사용한다.

Spring Data JPA에서 벌크성 수정 쿼리를 작성할 때는 @Modifying 애너테이션이 붙는다.
벌크 연산은 영속성 컨텍스트를 무시하고 바로 데이터베이스에 쿼리를 보내기 때문에 영속성 컨텍스트로 관리되는 엔티티의 상태와 데이터베이스에 저장된 데이터가 서로 일치하지 않는 경우가 발생할 수 있다.
따라서 벌크 연산을 수행한 이후 flush와 clear함수를 실행해 영속성 컨텍스를 초기화 하는 방법을 사용하자.
@Modifying(clearAutomatically = true) 로 설정하면 해당 애너테이션이 붙은 메서드가 실행된 후 영속성 컨텍스트가 자동으로 초기화된다.
Spring Data JPA에서는 JPA를 다루면서 발생했던 N+1문제를 JPQL을 작성하는 대신 @EntityGraph 애너테이션을 사용해서 깔끔하게 해결한다.
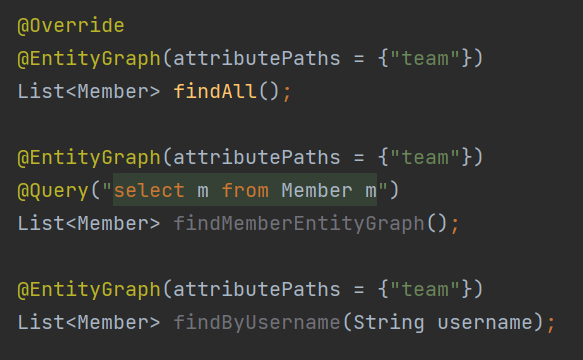
JPA만 사용할때는 JPQL에 Fetch Join을 추가해서 작성해야 됐지만, 이제는 더 쉽게 해결할 수 있다.
JPQL과 @EntityGraph 애너테이션을 함께 사용하는 것도 가능하다.
내부적으로는 Fetch Join을 사용하니.. 사실상 Fetch Join의 간편화된 버전이라고 생각하면 된다.
반응형
'Spring > Spring Data JPA' 카테고리의 다른 글
| [Spring Data JPA] 내부 동작 원리 (0) | 2023.01.03 |
|---|---|
| [Spring Data JPA] 사용자 정의 리포지토리와 확장 기능 (0) | 2023.01.03 |
| [Spring Data JPA] 쿼리 메서드와 페이징 (0) | 2023.01.02 |
| [Spring Data JPA] 공통 인터페이스 (0) | 2023.01.02 |