[Computer Network] Router
인터넷은 Packet Switched Network.
데이터는 IP 패킷으로 쪼개져서 전송되고, 라우터는 패킷 교환망의 교차로에 있는 신호등 역할을 수행한다.
즉, Input Port로 들어온 패킷을 적절한 Output Port로 연결해줌.
경로를 만드는거랑 실제로 패킷을 전달하는건 다름.
Routing은 출발지부터 목적지까지의 전체 경로를 결정하는 과정으로, Routing Table을 기반으로 수행된다.
최단 경로, 정책 기반 등 경로 탐색 알고리즘을 사용함.
Forwarding은 Input Port로 들어온 패킷을 Output Port로 실제로 넘겨주는 작업.
Forwarding Table을 검색해 어디로 보낼지 결정한다.

Control Plane - Software
상단의 Routing Processor가 담당하는 영역으로, Routing 기능을 수행한다.
프로토콜을 돌리고, 경로를 게산하고, Routing Table을 관리한다.
소프트웨어 기반으로 처리하다 보니 상대적으로 느리다. (millisecond 단위)
Data Plane - Hardware
Input Ports, Output Ports, Switching Fabric으로 구성된다.
Forwarding을 처리한다. 들어온 패킷을 바로바로 내보내야 하니 굉장히 빨라야 함.
하드웨어 수준에서 처리하니 Nanosecond 단위로 동작한다.
Input Port는 단순히 신호만 받는게 아님. 여러 가지 역할을 수행한다.
특히 고성능 라우터는 Input Port에 Forwarding Table의 복사본을 저장하고 있어 독자적으로 판단하는 경우도 있음.
또, 포워딩 할 때도 IP 주소만 보지 않고 출발지, 목적지 등 헤더의 다양한 값을 보고 판단한다.
Line Termination - 케이블을 타고 들어온 신호를 비트로 변환
Link Layer Protocol - 이더넷같은 프로토콜을 처리해 비트를 의미 있는 데이터로 만듦
Lookup, Forwarding, Queueing - 중앙 프로세서를 거치지 않고 입력 포트가 독자적으로 판단하기도 함

Forwarding Table은 목적지 - 나가는 문 Pair로 구성된다.
패킷이 들어오면 패킷 헤더의 목적지 주소를 추출하고, 테이블에서 그 주소를 찾아 특정 위치로 보낸다는 명세를 수행한다.
패킷의 순서를 맞추는건 어차피 TCP가 하니까 라우터는 어떻게 보내든 알빠가 아님.
라우터가 전 세계 모든 IP 주소를 1:1로 저장하는건 불가능하다. 그러니 주소의 범위를 저장하게 되는데..
패킷 주소가 여러 범위에 동시에 해당하는 경우가 있음.
이러면 Longest Prefix Match 쪽으로 보낸다. (구체적이고 좁은 범위를 정의한 규칙을 따라감)
근데 이런 비슷한 개념 다른 쪽에서도 많이 있지 않나? 받아들이기 어렵지 않음.
Routing Table에 규칙이 많으면 브루트포스 치기 힘들다. Trie 자료구조를 쓴다.
백준에서 많이 풀었으니까 설명은 됐고.. IP 주소는 0과 1로 구성되니 이진트리 형태로 경로를 찾을 수 있어 효과적임.
Binary Trie는 IP주소가 32비트라고 치면 최대 32번 내려가야 해서 메모리 접근 횟수가 많다.
이걸 해결하기 위해 리눅스 커널에서는 Level Compressed Trie를 사용한다.
Path Compression - 자식이 하나밖에 없는 경로에서는 한번에 점프
Level Compression - 트리의 특정 부분을 꽉 채워서 한 번에 여러 비트를 처리하도록 함. (이걸 위해 메모리를 좀 더 사용한다)

라우터 내부에서 패킷이 실제로 어떻게 이동하는지를 다루는 Router Switching 구조에는 세 가지가 있다.
1. Memory
제일 초기 방식으로, CPU가 직접 개입한다.
Input Port에 패킷이 오면 CPU에게 인터럽트를 걸고 CPU가 패킷을 메모리로 복사한 후 Output Port로 복사한다.
System Bus를 두 번 타야 해서 속도가 가장 느리다.
2. Bus
CPU를 거치지 않고 모든 Input Port와 Output Port가 하나의 Shared Bus에 연결됨.
버스 사용 권한을 얻으면 패킷을 전송한다.
3. Interconnection Network
여러 개의 선을 교차해서 만든 Grid 구조. CrossPoint를 닫아서 길을 만든다.
병렬 처리가 가능해 고성능 라우터에서 사용한다.

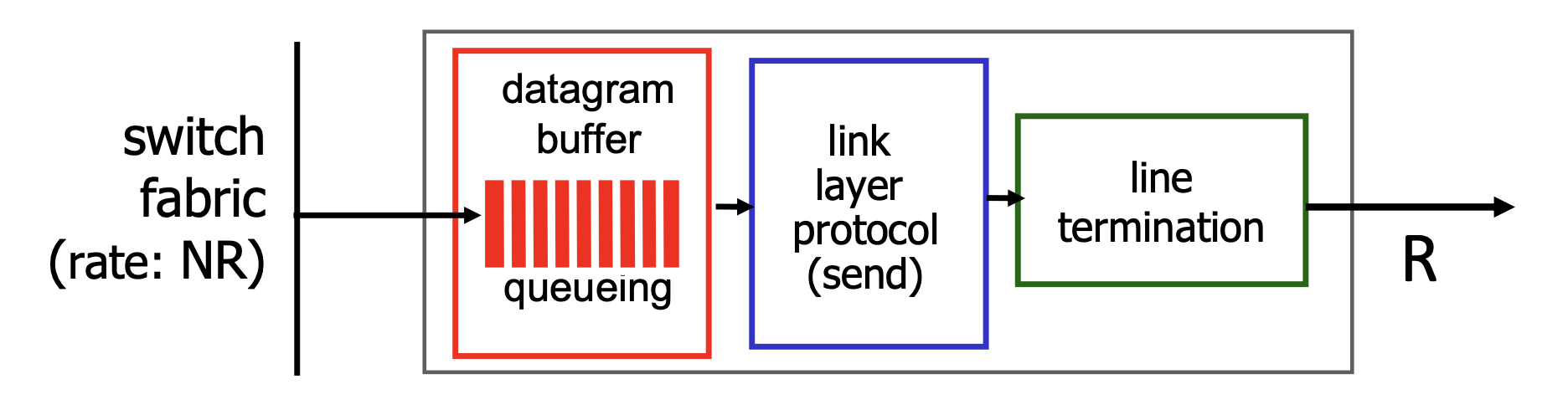
Input Port의 속도가 Router Switching보다 빠르면 큐에 패킷이 쌓인다.
맨 앞 때문에 뒷부분이 이동할 수 없는 HOL이 발생한다.
Switching이 완료되더라도 Output Port에 패킷이 몰려들면 여기서도 큐잉이 발생한다.
스위치에서 넘어오는 속도가 내보내는 속도보다 빠르면 버퍼에 잠시 저장하고, 버퍼가 꽉 차면 선택한 알고리즘에 따라 버린다.
최근에는 BufferBloat 이슈도 있음. 버퍼가 크다고 무조건 좋은게 아니다.
네트워크 장비의 버퍼가 너무 커서 패킷이 버려지지 않는 현상인데..
패킷을 버리면 아까우니까 버퍼를 크게 잡았는데, 라우터가 꾸역꾸역 다 받아주니까 TCP는 혼잡한줄 모르고 계속 데이터를 쏴버린다.
패킷들은 버퍼에 갇혀서 나갈 차례만 쭉~ 기다리게 됨.
인터넷 반응 속도는 개 느린데 대역폭은 빠른 상황 -_-
그래서 Input Port에 Output Port별로 따로 큐를 둬서 HOL을 해결하고, Active Queue Management 방식을 사용해 버퍼가 꽉 차기 전에 패킷을 확률적으로 버려 BufferBloat 문제를 완화함.
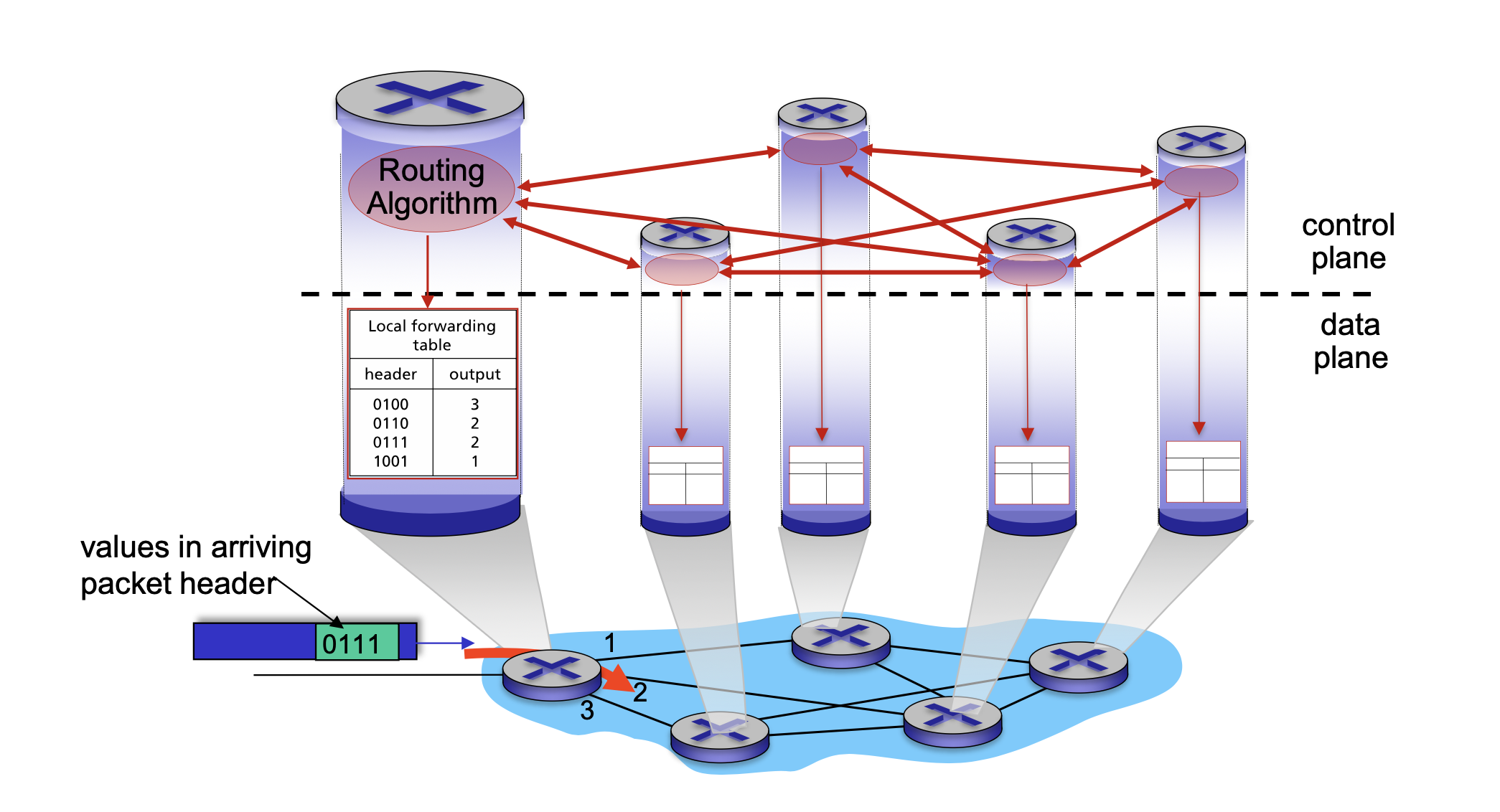
Control Plane
라우팅 알고리즘이 수행되는 곳으로, 네트워크 지도를 그리고 어디로 가는게 가장 빠른지를 계산한다.
여기서 Forwarding Table이 만들어짐.
Data Plane
실제로 패킷이 들어오면 위에서 만들어 준 Forwarding Table만 보고 패킷을 전달한다.
즉, 머리쓰는건 Control Plane에서 수행하고 Data Plane에서는 전달만.
라우팅 문제는 그래프에서의 최단거리 탐색 문제와 같음.
라우터를 노드로 잡고 라우터들을 연결하는 링크를 간선으로 잡으면 그래프가 완성된다.
비용을 정의할 때는 대역폭에 반비례하도록 설정할 수 있고, 혼잡도에 따라 설정할 수 있음.
Global
모든 라우터가 네트워크 전체 지도 (Topology) 와 비용을 완벽하게 알고 시작하는 관점이다.
Link State Algorithm - 모든 라우터가 정보를 방송해 공유한 뒤 계산한다.

출발지로부터 모든 목적지까지의 최단 경로를 계산하는 다익스트라를 수행하자.
현재까지 발견된 최단 비용과 바로 직전의 노드(역추적)를 저장한다.
우선순위큐 써서 작은 비용을 먼저 보고, 경로 계산해서 더 빠르면 업데이트한다.
알고리즘이 끝나면 각 목적지별로 누구한테 보내야 제일 빠른지가 결정됨.
이 정보가 Forwarding Table 그 자체.
Link State 방식(OSPF)은 전체 지도를 가지고 다익스트라 때려서 최적 경로를 계산함.
Decentralized
전체 정보를 모른다. 내 옆에 뭐가 있고, 거기로 가는 비용 정도만 알고 있음.
Distance Vector Algorithm - 이웃이 전해주는 정보를 믿고 계산한다.
Link State Algorithm은 트래픽 양을 비용으로 설정할 때 Oscillation 문제가 발생한다.

처음에는 트래픽이 위아래 경로로 적절히 나눠서 흐르다가, 라우터가 계산해보니 위쪽길은 비용이 높고 아래쪽은 비용이 낮다고 판단한다.
모든 라우터가 동시에 아래쪽으로 경로를 바꿔버린다. 이제 아래쪽 길이 꽉 막힌다.
이게 반복되면서 트래픽이 왔다갔다함;; 네트워크가 불안정해진다.
방지하기 위해서는 라우터마다 경로 갱신 주기를 조금씩 다르게 해 줘야 함.

Distance Vector Algorithm은 벨만-포드를 사용한다.
옆에 있는 노드에게 목적지로 갈 때의 비용을 물어보고 가장 작은 값을 선택한다.
전체 지도를 모르고 내 옆 노드랑 정보를 주고받는 과정을 반복함.
이웃이 거리 정보가 변경됐다고 알려주거나 자신의 링크 비용이 변했을 때 다시 벨만-포드를 돌려서 업데이트해줌.
링크 비용이 줄어드는 경우에는 문제가 없지만, 링크가 끊어지거나 링크 비용이 증가할 때는 문제가 생김 - Count to Infinity
y -> x (4)
z -> y -> x (5)
여기서 z는 y를 믿고 있음.
y -> x 비용이 60으로 증가했다. y는 x로 가는 길을 다시 계산해야 함.
z한테 물어보니 x까지 가는 비용이 5밖에 안된다고 한다. 그런데, y는 z의 정보가 y를 거쳐서 나온 정보인줄 모르고 업데이트 해버림;
이제 실제 연결 비용에 도착할 때 까지 반복이 시작된다.
y -> x (6)
z -> y -> x (7)
y -> x (8)
z -> y -> x (9)
...
Poisoned Reverse 방식으로 루프를 끊을 수 있음.
z가 y에게 z에서 x로 가는 길이 없다고 거짓말하면, y는 링크 비용이 증가하더라도 z를 대안으로 선택하지 않는다.
2개 노드 사이의 루프는 막아주지만, 3개 이상의 노드가 엮여있는 경우는 막을 수 없음.
Distance Vector (RIP) 에서는 이 문제를 막을 수 없으니.. Threshold를 정해두고 경로 비용이 Threshold를 넘어가면 도달할 수 없다고 간주하는 방식으로 우회한다.
현실적으로 라우터에 모든 IP주소를 저장할 수 없으니 Hierarchical Routing 기법을 사용한다.
네트워크를 계층별로 나눠서 관리하고, 외부로 나갈 때는 세부적인 IP 주소를 하나로 묶어서 알린다.
CIDR 표기로 치면.. 168.188.0.0/16 처럼 대역을 하나로 묶어서 해당 대역으로 오는 패킷은 모두 이 라우터에게 보내달라고 알리는 방식임. 이러면 외부 라우터들은 여러 세부 주소 대신 축약된 주소 하나만 알면 된다.
인터넷은 Autonomous System 단위로 인터넷을 관리한다. 대학도 하나의 AS이고.. KT나 SKT같은 ISP도 각각 하나의 AS.
Intra-AS Routing
AS 내부의 모든 라우터는 동일한 라우팅 프로토콜을 사용해야 한다. (RIP, OSPF)
Inter-AS Routing
서로 다른 AS끼리 통신할 때는 AS의 경계에 있는 Gateway 라우터들이 이 역할을 수행한다. (BGP 프로토콜)

공대 5호관에서 정보화본부로 가는 길은 Intra-AS Routing 프로토콜인 RIP, OSPF가 결정해서 Forwarding Table에 채워넣는다.
AS 외부로 뻗더나가는 경로는 두 프로토콜이 협력해야 함.
공대 5호관에서 구글에 접속할 때는 Inter-AS Routing이 구글 AS위치를 가져오고, Intra-AS Routing이 구글로 가기 위한 학교 AS의 Gateway까지의 경로를 가져온다.
라우터 입장에서는 경로가 내부에서 왔든 외부에서 왔든 통합된 Forwarding Table에 저장해 패킷을 처리한다.
그림에서는 1b와 1c가 외부와 연결된 Gateway 라우터로 동작한다.
내부 라우터 1d가 외부로 나가는 패킷을 받으면, 가장 빠르게 밖으로 던질 수 있는 Gateway쪽으로 패킷을 보낸다. -Hot Potato Routing
Intra-AS Routing Protocol은 크게 세 가지로 구분된다.
RIP (Routing Information Protocol)
Distance Vector 알고리즘을 사용하고, 30초마다 이웃과 정보를 교환한다. (UDP)
지금은 잘 안씀.
Threshold로 16을 사용함. 그러니 최대 15hop까지만 도달할 수 있다.
그러니 대규모 네트워크에서는 사용할 수 없음.
인증 관련 로직이 없어서 가짜 패킷에 취약함. RIPv2에서는 패킷에 암호가 맞아야 라우팅 정보를 받아들인다.

UDP 520번 포트로 데이터를 보낼 때 전송하는 비트 구조.
command - 패킷이 요청인지 응답인지 구분한다. 평소에는 30초마다 응답을 보냄
version - RIPv1인지 RIPv2인지 구분
must be zero - 예약된 필드로 무조건 0이어야 함.
address family identifier - 주소 체계를 의미함. IPv4는 2번
IPv4 address - 목적지 네트워크 주소
metric - hop count
EIGRP (Enhanced Interior Gateway Routing Protocol)
RIP 진화버전 근데 이것도 잘 안씀.
OSPF (Open Shortest Path First)
Link-State 알고리즘을 사용하고, 가장 많이 쓰는 표준. RFC로 공개돼서 누구나 쓸 수 있다.
RIP처럼 hop만 따지는게 아니라 Link State Algorithm을 사용해 속도, 혼잡도도 함께 고려한다.
모든 라우터가 네트워크 전체의 연결 정보를 서로 공유하고, 모두가 동일한 Topology를 가지게 됨.
다익스트라로 Forwarding Table을 채워넣는다.
TCP나 UDP를 사용하지 않고 IP 패킷 위에 직접 OSPF 메세지를 추가해서 전달함.
여기서 모든 OSPF 메세지에는 인증을 추가할 수 있다.
라우터가 너무 많으면 모든 라우터가 Topology를 가지는게 부담스러울 수 있음. AS 내부를 또 작은 구역으로 쪼갠다.
Two-Layer Hierarchy
Backbone이 모든 구역을 연결하는 중심 고속도로 역할을 수행한다. Local Area는 Backbone에 연결된 하위 그룹.

Internal Routers는 특정 Area 내부에만 속한 라우터로, 자기 구역 내부 정보만 알고 있으니 구역 내 라우팅만 계산한다.
Area Border Router는 Area와 backbone을 연결하는 다리 역할을 수행해 구역 패킷을 외부로 보낼 때 백본으로 전달한다.
Inter-AS Routing은 BGP (Border Gateway Protocol) 으로 처리된다.
eBGP (External BGP) - 외부 라우터와 연결되어 AS 밖 정보를 얻어옴
iBGP (Internal BGP) - eBGP를 통해 밖에서 얻어온 정보를 내부 라우터들에게 전파한다.
OSPF는 가장 빠른 길을 찾지만, BGP라우팅은 Reachability와 Policy를 고려해 경로를 결정한다.
A 경로가 더 빠르지만 B 경로를 쓰면 내가 깔아둔 회선을 탈 수 있으면.. B 경로를 선택해야 함.
BGP 라우터들은 서로 정보를 주고받을 때 TCP를 사용한다.
다른 라우팅 프로토콜들은 IP 위에서 바로 동작하거나 자기내들이 알아서 만든 전송방식을 쓰는데.. BGP는 신뢰성이 매우~ 중요하기에 TCP를 통해 안정적으로 연결해야 함.

3a 라우터는 2c에게 정보를 보낸다. - 네트워크 X로 가고 싶으면 AS 3로 와야 함~
BGP Advertisement는 이 정보를 전달하는 작업을 말한다.
BGP는 Path Vector 프로토콜이다.
단순히 X까지 n칸 남았다고 알려주는게 아니라, X까지 가려면 AS 2 -> AS 3 로 가야한다고 전체 경로 리스트도 알려준다는 것.
왜? 전체 경로를 다 보여줘야 라우터가 루프를 피할 수 있으니까..
1. Prefix (목적지 주소)
CIDR 표기법으로 어디로 가야할 지 정의한다.
2. Attributes
목적지 뿐만 아니라 그 길의 특성을 설명하는 정보를 함께 전달한다.
AS-PATH로 목적지까지 가기 위한 AS들의 리스트를 함께 전달.
NEXT-HOP으로 다음 AS로 넘어가기 위해 데이터를 던져줘야 할 구체적인 라우터의 IP주소를 전달.
3. Policy-Based Routing
Import Policy로 남이 준 정보를 받아들일지 말지를 결정하고,
Export Policy로 내가 아는 정보를 남에게 알려줄지 말지를 결정한다.

AS 3 안에 있는 네트워크 X의 존재를 전 세계에 알려보자.
1. AS 3 -> AS 2
3a가 2c에게 AS 3을 통해 X로 갈 수 있다고 메세지를 보낸다.
여기서는 외부와 통신하니 eBGP를 사용함.
2. AS 2 내부 전파
정보를 받은 라우터 2c는 AS 2 내부의 모든 라우터에게 이 사실을 알려준다.
이제 AS 2 내부의 모든 라우터가 X로 가기 위해 2c -> 3a 경로를 이용하면 됨을 알게됨.
3. AS 2 -> AS 1
2a가 1c에게 AS 2를 통해 AS 3로 갈 수 있고, AS 3를 통해 X로 갈 수 있다고 메세지를 보낸다.
AS-PATH가 AS 2, AS 3, X 로 업데이트된다. (Path Vector)
실제 라우터 내부에서는 이런 정보들이 테이블로 저장됨. show ip bgp로 확인해보자.

뒤에 있는 Path 부분이 AS-PATH를 나타낸다. 저 Path Vector 덕분에 루프가 발생하지 않음.
전 세계 라우터들이 목적지마다 갈 수 있는 수많은 Path Vector를 가지고, 저 리스트 중 가장 좋은 길(>) 하나를 선택해 통신한다.
BGP 라우터가 주고받는 대화의 종류는 4가지.
OPEN - TCP 연결을 맺은 후 가장 먼저 보내는 메세지로, Authentication과 기본 정보 교환을 수행함.
UPDATE - Path를 수정할 때 사용한다. 새로운 경로를 광고하거나 기존 경로를 수정함.
KEEPALIVE - UPDATE할 정보가 없어서 라우터가 가만히 있으면 죽었다고 오해할 수 있음. 60초마다 한 번씩 찔러준다.
NOTIFICATION - 이전 메세지에 오류가 있거나, 인증에 실패하는 등 뭔가 잘 안될때 발생한다.
AS 내부에서 라우팅 정보를 전달할 때는 Interior Gateway Protocol을 사용한다. (OSPF 같은 내부 라우팅 프로토콜)
단순히 거리가 짧다고 선택하지 않는다. Policy가 우선됨.
Local Preference - AS마다 선호하는 길이 있다. 값이 클수록 우선순위가 높음.
Shortest AS-PATH - Local Pref로 결정되지 않으면 거리를 비교함.
Closest NEXT-HOP - 위에 두 개로도 안되면 Hot Potato 전략을 사용한다. 그냥 가장 가까운 출구로 던짐
MED (Multi-Exit Discriminator) - 이것도 똑같으면 상대방 AS의 요청을 들어준다. 값이 낮을수록 우선순위가 높음
2021 10.25에 KT 인터넷 장애가 터졌을 때도 라우팅 설정 오류가 원인이였음.
외부 라우터와 경로 정보를 교환할 때는 BGP를, 내부 라우터와 경로 정보를 교환할 때는 IS-IS를 사용한다.
IS-IS 프로토콜 설정을 마무리하고 나와야 했는데 exit 명령어를 안 치고 BGP 설정을 진행해버려서.. BGP가 가지고 있든 경로 정보가 IS-IS 프로토콜으로 재분배됐음.
IS-IS는 BGP 정보를 감당하지 못하고 터져버렸고.. 오류 정보가 연결된 다른 라우터들로 전파되면서 전국망이 마비됨.
통신사 여러개와 연결해두면 통신사 하나가 터지더라도 다른 통신사와 연결해 연결을 유지할 수 있다.
Multi-Homing이 구현되어있지 않고 통신사 하나에만 의존한다면.. 죽으면 끝나는거임.
디비 이중화랑 비슷한 맥락이다.
Path Change와 Withdrawal으로 네트워크가 터졌으니 Announce로 다시 끊어진 인터넷을 연결해야 함.

KT에서 SK로 갈아탄 경우가 가장 많고, KT에서 KREONET으로 갈아탄 경우가 두 번째로 많음.
위기 상황에서 Multi-Homing이 작동해 트래픽을 받아냈다.
다만 Transit 설정 실수가 발생하면 일개 단체의 네트워크가 거대 통신사들을 잇는 다리 역할을 맡게 되고 트래픽 과부하로 터질 수 있음.
그렇다고 가정용 인터넷으로 전체 통신사를 터뜨리는건 불가능. 통신사와 BGP 통신을 하지 않고, DHCP서버로부터 IP 하나를 빌릴 뿐임.
Announce Withdrawal Path Change로 라우터 내부의 Routing Table을 조작한다고 보면 됨.
'Computer Science > Computer Network' 카테고리의 다른 글
| [Computer Network] Multimedia Streaming (0) | 2025.12.14 |
|---|---|
| [Computer Network] IP Address (0) | 2025.12.13 |
| [Computer Network] Congestion Control (0) | 2025.11.02 |
| [Computer Network] Transmission Control Protocol (1) | 2025.10.15 |
| [Computer Network] Transport Layer Security (0) | 2025.10.14 |