[Fault Injection] 라즈베리파이 Bit-Flip을 HPC로 잡아내기 - 1
목표는 A Micro Architectural Events Aware Real-Time Embedded System Fault Injector 논문 구현하기.
직접 모델을 학습시켜서 Edge Device가 공격받는 경우를 인지하는 시스템을 구축해보자.
AI 모델을 학습시키기 위해 두 가지 데이터가 필요하다.
1. 정상 상태의 HPC 데이터 (collect_ptrace_normal.py)
2. Bit-Flip으로 결함이 발생한 상태의 HPC 데이터 (collect_native_fault.py)
소스코드는 여기 참고
하드웨어는 라즈베리파이 4를 사용함.
pi@raspberrypi:~ $ sudo apt update
Hit:1 http://deb.debian.org/debian bookworm InRelease
Hit:2 http://deb.debian.org/debian-security bookworm-security InRelease
Hit:3 http://deb.debian.org/debian bookworm-updates InRelease
Hit:4 https://deb.nodesource.com/node_18.x nodistro InRelease
Hit:5 http://archive.raspberrypi.com/debian bookworm InRelease
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
394 packages can be upgraded. Run 'apt list --upgradable' to see them.
pi@raspberrypi:~ $ sudo apt install -y linux-perf
..
pi@raspberrypi:~ $ perf --version
perf version 6.12.47
pi@raspberrypi:~ $
CPU 내부 상태를 들여다봐야 하니까.. perf를 설치해준다.
perf는 PMU에 접근해 하드웨어 이벤트를 읽어온다.
커널 수준에서 동작하기에 시스템 성능에 영향을 주지 않으면서 데이터를 수집할 수 있음.

perf list 명령어로 하드웨어가 어떤 이벤트를 감지할 수 있을 지 확인해보자.
여러 지표 중 cycles / instructions / cache-misses / branch-misses 네 가지를 사용한다.
저 네 가지 지표는 Bit-Flip이 발생했을 때 가장 민감하게 반응하는 핵심 지표로, 모델을 학습시킬 때도 저 네 가지 지표만 사용할 예정.
/*
* 벤치마크는 Marvin 논문 그대로 사용함
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#define BENCHMARK_BASICMATH 1
#define BENCHMARK_QSORT 2
#define BENCHMARK_SHA 3
#ifndef BENCHMARK
#define BENCHMARK BENCHMARK_BASICMATH
#endif
#if BENCHMARK == BENCHMARK_BASICMATH
double basic_math_compute(int n) {
double result = 0.0;
for (int i = 1; i <= n; i++) {
double x = (double)i;
double sqrt_approx = x / 2.0;
for (int j = 0; j < 10; j++) {
sqrt_approx = (sqrt_approx + x / sqrt_approx) / 2.0;
}
double angle = (double)i / 1000.0;
double sin_approx = angle;
double term = angle;
for (int j = 1; j < 10; j++) {
term *= -angle * angle / ((2*j) * (2*j + 1));
sin_approx += term;
}
result += sqrt_approx + sin_approx;
}
return result;
}
int main() {
printf("Starting Basic Math Benchmark\n");
volatile double result = basic_math_compute(10000);
printf("Result: %.6f\n", result);
return 0;
}
// ============================================
// Quick Sort Benchmark
// ============================================
#elif BENCHMARK == BENCHMARK_QSORT
void swap(int* a, int* b) {
int t = *a;
*a = *b;
*b = t;
}
int partition(int arr[], int low, int high) {
int pivot = arr[high];
int i = (low - 1);
for (int j = low; j <= high - 1; j++) {
if (arr[j] < pivot) {
i++;
swap(&arr[i], &arr[j]);
}
}
swap(&arr[i + 1], &arr[high]);
return (i + 1);
}
void quickSort(int arr[], int low, int high) {
if (low < high) {
int pi = partition(arr, low, high);
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
int main() {
printf("Starting Quick Sort Benchmark\n");
int n = 10000;
int* arr = (int*)malloc(n * sizeof(int));
srand(42);
for (int i = 0; i < n; i++) {
arr[i] = rand() % 10000;
}
quickSort(arr, 0, n - 1);
int sorted = 1;
for (int i = 0; i < n - 1; i++) {
if (arr[i] > arr[i + 1]) {
sorted = 0;
break;
}
}
printf("Result: %s\n", sorted ? "Sorted correctly" : "Sort failed");
free(arr);
return 0;
}
// ============================================
// SHA-like Hash Benchmark
// ============================================
#elif BENCHMARK == BENCHMARK_SHA
unsigned int rotate_left(unsigned int value, int shift) {
return (value << shift) | (value >> (32 - shift));
}
void sha_like_hash(const unsigned char* data, int len, unsigned int hash[5]) {
hash[0] = 0x67452301;
hash[1] = 0xEFCDAB89;
hash[2] = 0x98BADCFE;
hash[3] = 0x10325476;
hash[4] = 0xC3D2E1F0;
for (int i = 0; i < len; i++) {
unsigned int temp = rotate_left(hash[0], 5) + hash[4] + data[i];
hash[4] = hash[3];
hash[3] = hash[2];
hash[2] = rotate_left(hash[1], 30);
hash[1] = hash[0];
hash[0] = temp;
}
}
int main() {
printf("Starting SHA-like Hash Benchmark\n");
int data_size = 100000;
unsigned char* data = (unsigned char*)malloc(data_size);
for (int i = 0; i < data_size; i++) {
data[i] = (unsigned char)(i % 256);
}
unsigned int hash[5];
sha_like_hash(data, data_size, hash);
printf("Hash: %08x %08x %08x %08x %08x\n",
hash[0], hash[1], hash[2], hash[3], hash[4]);
free(data);
return 0;
}
#endif
벤치마크는 논문과 유사하게 QuickSort / SHA / BasicMath / 단순반복문을 사용한다.
준비해 둔 py 파일을 실행시키면 4가지 csv 데이터를 얻을 수 있음. (하나는 정상, 나머지는 Bit-Flip)
Marvin 논문은 Xilinx Zynq 기반 하드웨어를 사용해 XSCT를 통해 Fault Injection을 구현하지만, 라즈베리파이 4 에서는 XSCT를 사용할 수 없으니 GDB를 사용해서 Fault Injection을 구현한다.
애초에 Marvin의 핵심이 Fault 결과를 분류하고 로깅하는 방법론이니.. Bit-Flip의 발생 자체에 집중해야 함.
다만, 라즈베리파이 4에서 GDB로 Bit-Flip을 유도할 때는 GDB 내부에서 perf를 실행할 수 없어서 HPC 측정이 어렵다.
기본적으로 perf stat은 자식 프로세스 전체를 측정하는데, GDB가 벤치마킹 중 하나를 실행하면 perf는 GDB와 벤치마크 모두를 측정한다.
그러니 HPC에 디버깅 심볼 로드, 브레이크포인트 설정, 명령어 파싱 등 모든 작업이 포함됨.
Marvin 논문에서는 XSCT로 외부에서 JTAG를 통해 레지스터를 조작하는 방식이라 XSCT의 오버헤드가 HPC에 포함되지 않음.
그러니 Marvin을 구현하려면 GDB 말고 Ptrace를 사용해 프로세스 외부에서 레지스터를 조작하는 방식으로 구현해야 한다.
GDB를 사용할 때는 측정 도구의 오버헤드가 너무 커서 실제 Bit-Flip 효과를 가리니 Ptrace 방식을 사용하자.
Bit-Flip 을 발생시킬 때의 타이밍, 대상 레지스터 등을 잘 고려해서 데이터를 수집해야 함.
...
라고 생각했는데 실제로 Ptrace 방식으로 Bit-Flip을 유도하고 데이터를 시각해봤는데..
정상 데이터랑 차이가 크지 않았음.
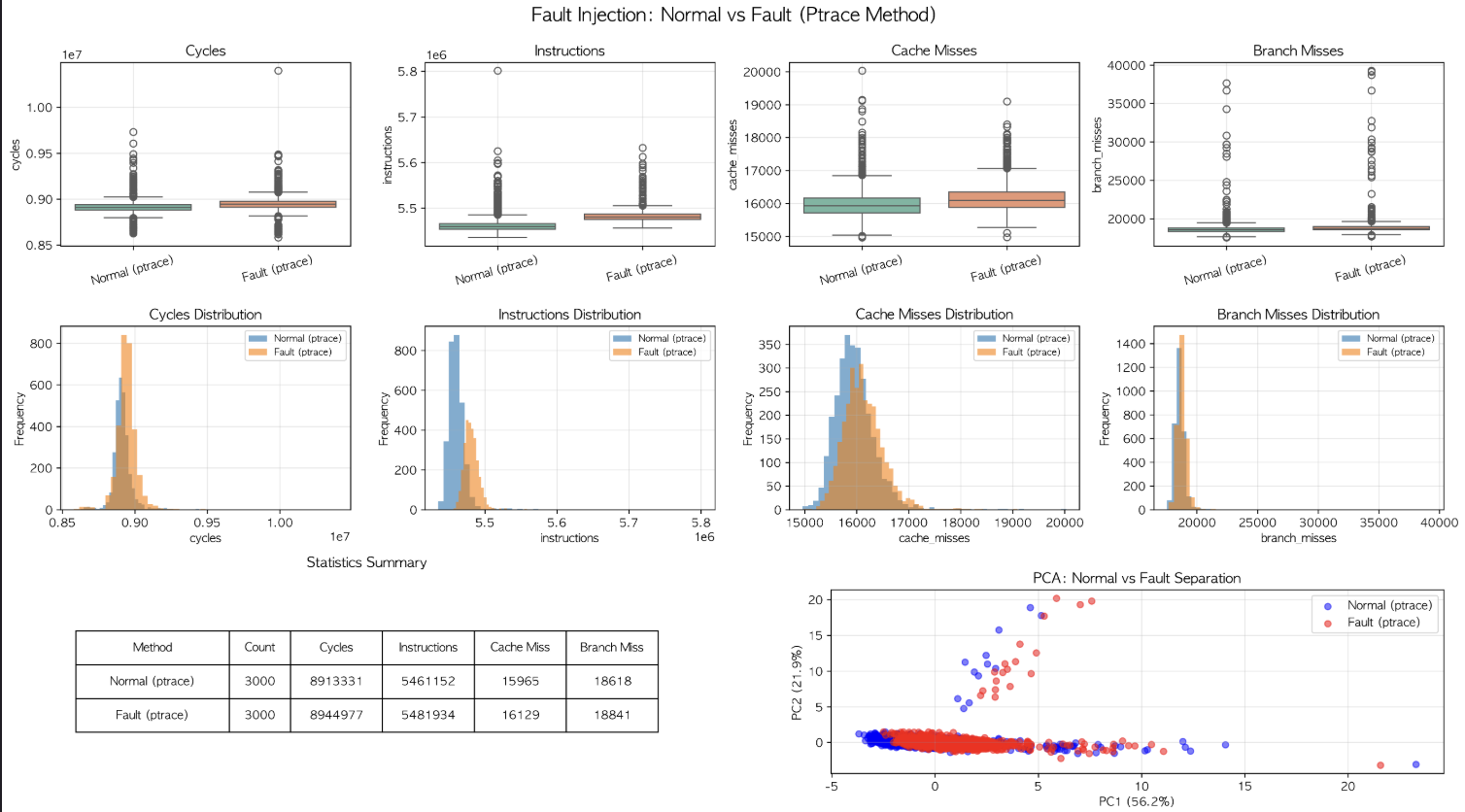
프로그램 시작 시점에만 Bit-Flip이 발생하게 되면 HPC 로 잡아낼 수 없음.
Marvin 논문을 보면 프로그램 실행 중간에 Bit-Flip을 발생시키는데, Ptrace로는 이게 힘들다.
그러니 라즈베리파이에 GPIO 써서 JTAG 디버거를 연결하든지 해야함..
이게 힘들면 프로그램 코드 자체에 Bit-Flip을 삽입해두는 방법도 있다. 이 방법으로 다시 트라이해보자.

제대로 된 데이터를 수집하려면.
1. 계산 중간에 Fault Injection을 수행하고
2. 실제로 사용하고 있는 변수를 Bit-Flip 하고
3. 그 변수가 덮어쓰여지지 않아야 한다.
LLFI 에서도 LLVM IR 수준에서 Bit-Flip 을 발생시키니까 사실상 코드 수준에서 공격하는거랑 마찬가지.
그런데 이 방법으로 논문을 작성하는건 힘드니까.. 다른 방법을 생각해보기..
일단 여기까지의 시행착오를 정리..
1. GDB를 사용해 레지스터를 직접 수정하는 경우
gdb --batch
-ex 'break main'
-ex 'run'
-ex 'next' # 3줄 실행
-ex 'next'
-ex 'next'
-ex 'set $x0 = $x0 ^ (1<<5)' # bit-flip
-ex 'continue'
GDB 자체가 너무 무거워서 제대로 측정할 수 없다.
정상 상태에서는 30M cycles / GDB를 돌리면 1.2B cycles가 측정됨.
즉.. cycles이 Bit-Flip 때문에 늘어났는지 GDB 때문에 늘어났는지 알 수 없음.
2. Ptrace를 사용해 Bit-Flip을 유도하는 경우
리눅스 System Call인 Process Trace을 사용함.
fork() // 자식 프로세스 생성
ptrace(PTRACE_TRACEME) // 부모가 자식 프로세스를 추척
execl(target_program) // 자식 프로세스가 프로그램 실행
waitpid() // 대기
PTRACE_GETREGSET // 부모가 레지스터 읽음
regs[0] ^= (1 << 5) // 부모가 Bit-Flip 수행
PTRACE_SETREGSET //
PTRACE_CONT
프로그램 시작 직후에 Bit-Flip이 발생해버려서 실제 계산 전에 정상 값으로 덮어써진다.
그러니 HPC 지표에는 아무 변화가 없음.
이론상 Bit-Flip 발생 시점을 조작하면 되는데.. 조작할 때의 오버헤드가 너무 커서 GDB와 같은 문제가 발생함.
'💬 기록' 카테고리의 다른 글
| Edge Device와 Fault Injection - 세미나 발표 (0) | 2026.01.15 |
|---|---|
| PACK-UP v2.0 온보딩 - 세미나 발표 (0) | 2026.01.02 |
| HOBBIT을 사용한 최적화 - 세미나 발표 (0) | 2025.12.31 |
| 프론트엔드 아키텍처와 Feature-Sliced Design (2) (0) | 2025.12.02 |
| [eziwiki] Static Site Genearator with Markdown (0) | 2025.11.28 |