Machine Learning - Supervised Learning (2)
Supervised Learning의 여러 가지 알고리즘들에 대해 살펴보자.
1. Naïve Bayesian Classifier
2. Decision Tree
3. K-Nearest neighbor
4. Linear Models
5. Support Vector Machine (SVM)
6. Multi Layer Perceptron(MLP)
Linear Model은 Neural Network와 Deep Learning의 기반이 되기 때문에 자세히 알아둬야 한다.
2. Decision Tree (Classification)
결정 트리, Tree Structure 라고도 불린다.

node : 질문들
branch : 질문의 답에 대한 분기
이미지를 Decision Tree에 집어넣고, 질문을 한다.
손가락이 몇 개?
다리가 몇 개?
등등...
이런 질문들은 Feature Vector에서의 Feature에 관련돼있다. (분야의 전문가가 개입)
이런 질문들에 따라서 다른 질문들로 가게 된다. (나무의 branch를 생각하자)
스팸 메일을 구분하는 Decision Tree를 생각해보자.
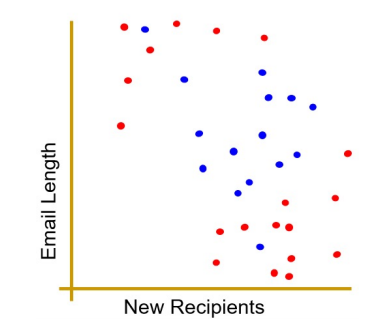

학습 데이터로 이메일을 받고, 자질로 길이, 수신자 수를 받는다.
결과로는 SPAM / HAM 가 있다.

이메일의 길이를 기준으로 스팸인지 아닌지 결정하는 Decision Tree 형식으로 질문을 만든다.
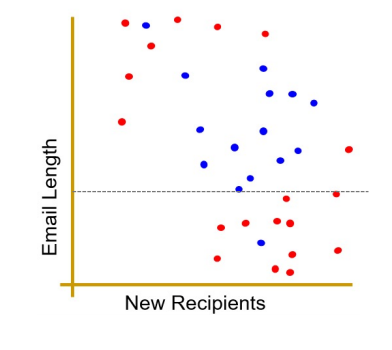
위와 같은 기준으로 분류하게 되면, 하나의 메일이 스팸으로 오분류되는 상황이 발생한다.
이를 바탕을 계속해서 피드백을 거쳐 질문들을 갱신한다.
계속해서 질문을 갱신하면
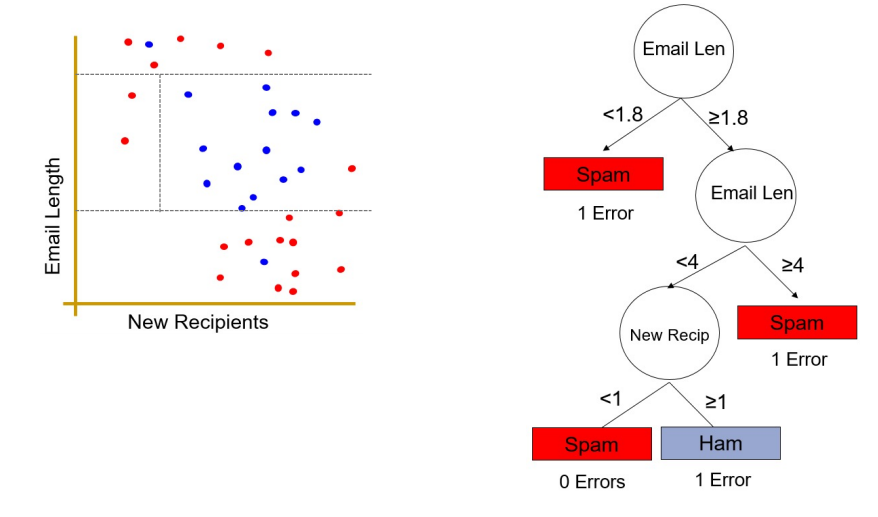
이렇게 연속되는 질문들을 통해 boundary를 좁혀가며 스팸 메일을 구분하는 Decision Tree를 완성시킨다.
하지만, 이렇게 분류했지만 boundary밖에 아직 스팸메일이 아닌 메일이 있다. 이 메일들까지 분류하기 위해서는 에러에 대해서 계속해서 질문들을 던지는 방법이 있지만..
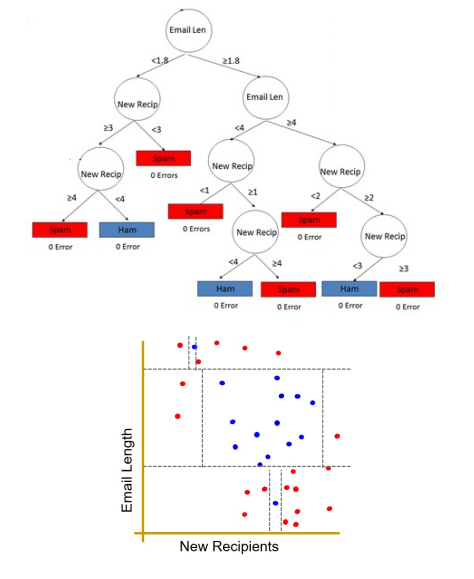
작은 오류들을 잡기 위해 질문들의 크기가 훨씬 더 커졌다.
Training Set을 통해 Decision Tree를 만들었는데, 학습의 목표는 Training Set에서 에러를 줄이는 것이 목표가 아니라 Testing에서의 에러를 줄이기 위함을 목적으로 한다.
즉, 일반화에 집중해서 학습을 진행해야 한다.

위의 두 가지 Decision Tree 중에서 첫 번째 트리가 더 좋은 트리라고 말할 수 있다.
위에서 말한 학습의 목적을 생각하며 그 이유를 생각해보자.
주어진 Training Set에서는 두 번째 트리가 더 좋다고 말할 수 있지만, 일반화 할 때를 생각해보자.
Training Set에서 오류가 없는 모델이 항상 좋은 모델이라고 말할 수 없다.
'Computer Science > Machine Learning' 카테고리의 다른 글
| Machine Learning - Supervised Learning (4) (0) | 2021.10.17 |
|---|---|
| Machine Learning - Supervised Learning (3) (0) | 2021.10.17 |
| Machine Learning - Supervised Learning (1) (0) | 2021.10.17 |
| Machine Learning (2) (1) | 2021.10.17 |
| Machine Learning (1) (0) | 2021.10.17 |