[Data Science] Data Preprocessing & Feature Engineering
실제 현장의 데이터는 깔끔하지 않다.
고객의 직업 정보가 비어있을 수가 있고, 연봉이 입력되는 칸에 -10처럼 음수가 들어가는 등 데이터에 노이즈가 포함될 수 있다.
그러니 데이터를 통해 제대로 된 결과를 얻으려면 Accuracy, Completeness, Consistency, Timeliless를 갖추도록 전처리가 필요하다.
Structure : 데이터의 형식을 의미한다. CSV / SQL / JSON / XML 등..
Granularity : 데이터 Row 하나가 뭘 의미하는지를 정의한다. 한 번의 구매? 한 명의 사용자?
Scope : 내가 분석하려는 목적에 맞는 범위인지 확인한다.
Temporality : 데이터가 언제 수집됐고, 주기성이 있는지 확인한다. (TimeZone 처리 포함)
Faithfulness : 데이터가 현실을 얼마나 잘 반영하는지를 의미한다. (이메일 형식, 미래 사건에 대한 과거 날짜 등..)

Quantitative (Continuous, Discrete) Qualitative (Nominal, Ordinal) 등 변수의 유형에 따라서 분석 기법이 달라지니 제대로 구분해주고,
데이터의 결측값을 어떤 전략으로 채워넣을지도 고려해준다. (제거하거나 평균 / 중앙 / 예측값으로 채워넣기)
이 때 데이터를 정렬한 후 Equi-depth 구간으로 나눠 값을 변환해 노이즈를 줄이는 Binning Method가 자주 사용된다.
당연히 Regression, Clustering으로 값을 채워넣기도 하고.. 사람이 직접 채우기도 한다.
데이터의 Source가 여러 개인 경우 데이터를 하나로 결합해서 일관된 데이터 저장소를 만들어야 한다. (Data Integration)
1. Schema Integration : 서로 다른 소스의 메타데이터를 통합하는 과정이다. (두 테이블의 cust-# 이 같은 속성일까?)
2. Data Value Conflicts : 동일한 개체에 대해 속성값이 서로 다르게 나타나는 경우이다. (누구는 미터법을, British Unit)
3. Handling Redundancy : 동일한 속성이 DB마다 다른 이름을 가질 때 발생한다.
중복된 속성을 찾아내기 위해 통계적 도구를 사용해서 두 변수 사이의 관계를 분석한다.
이 때 Pearson's Coefficient를 사용함.
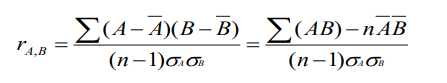
계산 값이 0이면 두 변수가 독립임을 의미하고, 양수와 음수 각각 양의 상관관계와 음의 상관관계를 의미한다.
공분산은 단위에 민감하니, 공분산을 각 변수의 표준편차로 나눠서 -1 ~ 1 사이로 표준화한다.
상관계수가 너무 높은 두 속성이 있다면.. 사실 두 속성은 중복 속성일 가능성이 크다.
이런 경우 데이터의 차원을 하나 줄이고 데이터 마이닝 속도를 높이는게 합리적.

공분산을 계산하면 상관계수와 유사하게 두 변수가 함께 변하는 정도를 알 수 있다.
양수라면 두 변수가 각자의 기댓값보다 커지는 경향이 있고, 0이면 독립일 가능성이 크다. (다만 비선형 관계일수도...)

Nominal (Categorical) 속성 간의 연관성을 파악할 때는 카이제곱 검정을 사용한다.
실제 관측값과 예측값의 차이가 클수록 두 변수는 서로 관련될 확률이 높다. (다만 상관관계가 있다고 해서 인과관계가 있는건 아님)
왜? 카이제곱 값은 우연히 일어날 법한 일과 실제로 일어난 일 사이의 거리를 측정하기 때문.
차이를 제곱하고 더하는 이유는 차이를 증폭시키기 위해서.. 값이 클수록 뭔가 관계가 있음을 유추할 수 있음.
상관계수를 시각화하면 데이터 통합 시 어떤 변수를 유지하거나 제거할 지 직관적으로 판단할 수 있다.
그냥 SQL 에서 조인치는것처럼 다 합치는게 아니고, 데이터의 Semantics를 이해하고 통계적으로 중복을 걸러내는 것...
모델의 성능은 데이터의 단위나 분포에 매우 민감하다. Data Transformation으로 분석에 적합한 수치 범위로 변환해야 함.
1. Min-Max Normalization
수식 너무 직관적이니 생략.. 값에서 최소 뺀거를 최대에서 최소 뺀거로 나눠주면 된다.
2. Z-Score Normalization
평균과 표준편차를 사용해 데이터를 정규분포 형태로 만든다. 이상치가 많을 때 유용.
3. Decimal Scaling
데이터의 절댓값 중 최댓값이 1보다 작아지도록 소숫점을 이동시킨다.
Numeric : 실수로 이루어진 값
Ordinal : 순서가 있는 값
Nominal : 순서가 없는 값
Numeric 값을 Discretization해서 다룰 수 있다. Unsupervised 인 경우 앞서 말했던 Binning Method를 자주 사용함.
구간의 너비를 일정하게 나누고, 각 구간에 들어가는 데이터의 개수를 일정하게 나누고, 데이터의 분포를 보고 빈도가 높은 곳을 기준으로 나눈다.
Supervised인 경우 Decision Tree를 사용하거나 상관관계가 높은 인접 구간들을 병합하는 방식을 사용. (Chi-merge)
Nominal과 Ordinal 값을 일반화 할 때는 Concept Hierachy를 사용해 Discretization과 유사한 효과를 낸다.
도메인 전문가가 직접 계층을 정의하거나, 고유값 개수를 분석해 자동으로 계층을 만든다.
Data Reduction의 목표는 분석 결과는 동일하게 유지하면서 데이터의 크기를 줄이는 것.
데이터가 많으면 데이터 분석 속도만 늦추니 꼭 필요하다.
Curse of Dimensionality - 차원이 늘어날수록 데이터가 Sparse해지고 점들 사이의 거리가 멀어져 분석의 의미가 옅어진다.
그러니 PCA, Wavelet Transform 으로 데이터를 가장 잘 설명하는 새로운 축을 찾거나 데이터를 압축한다.
데이터가 특정 모델에 적합하다고 가정하고, 데이터 대신 모델의 파라미터만 저장하는 방식도 가능하다.
또는 모델을 가정하지 않고 히스토그램, 클러스터링, 샘플링처럼 전체 데이터의 일부및 통계값만 저장하기도 함.
Wavelet Transform
데이터에 Smoothing를 수행하는 함수와 Difference를 계산하는 함수를 적용해 분해한다.
변환 결과 생성된 Coefficients들 중 값이 작은거는 0으로 대체하고, 의미 있는 계수만 저장해 데이터의 크기를 줄이는 방식이다.
Fourier Transform과 비슷하지만, Localized in Space하게 분포하게 되니 Lossy Compression 효율이 더 좋다.
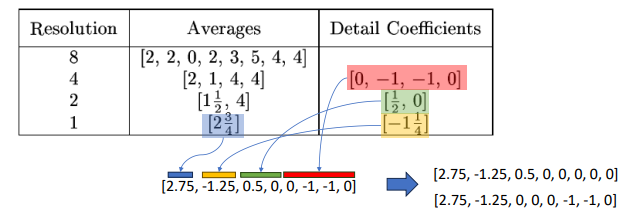
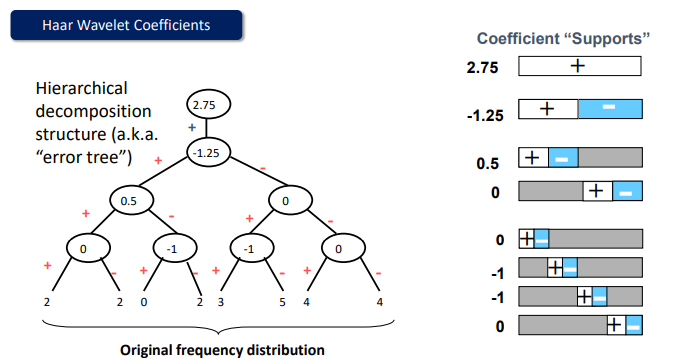
Haar Wavelet을 사용해 데이터를 변환한다고 하면, 먼저 데이터를 쌍으로 묶어서 평균과 차이를 적용한다.
Resolution이 8 -> 4 -> 2 -> 1 순서로 줄어들고 있음을 확인할 수 있다.
즉, 원본 데이터 2개를 보관하는 대신 평균 하나와 편균에서 얼마나 벗어났는지를 저장하는것.
차이값이 0에 가까운게 많을수록 압축 효과가 좋아진다.
이제 데이터 쌍의 차를 구하고, 최종 평균값과 각 단계에서 구한 세부 계수들을 합치면 변환이 완료된다.
계산 복잡도가 매우 빠르고 이상치 제거에 효과적이니 신호 처리 및 이미지 압축에 사용된다.
Principal Component Analysis
Wavelet Transform은 데이터를 시간과 주파수를 중심으로 압축하고, PCA는 데이터의 핵심 축을 새로 정의해서 차원을 확 줄여버린다.
데이터의 정보를 최대한 보존하면서, 원래 차원보다 더 작은 차원으로 데이터를 Projection 하는 것이 PCA의 목표.
PCA에서는 데이터가 가장 넓게 퍼져 있는 방향을 가장 중요한 정보로 간주한다.
기존 축 대신 데이터의 변동성을 가장 잘 설명하는 새로운 축을 찾고, 이 축을 Principal Components라고 부른다.
1. Normalization - 각 속성이 측정 단위에 따라 왜곡되지 않도록 범위를 맞춰준다.
2. Covariance Matrix - 데이터 내의 변수들이 서로 어떻게 변하는지 파악한다. (공분산을 활용)
3. Eigenvalues, Eigenvectors - 새로운 축의 방향과 그 분산의 크기를 결정한다.
고유값이 큰 순서대로 k개의 주성분을 선택하고, 나머지 약한 성분은 무시해 데이터의 크기를 줄이고 노이즈를 제거한다.
차원이 축소되니 당연히 데이터 크기도 줄어들고, 고차원 데이터를 시각화 할 때도 굉장히 유용하다.
사실 Wavelet Transform도 결과적으로는 원본을 그대로 저장하지 않고 핵심적인 Coefficients만 남기는 점에서 Numerosity Reduction과 동일하다.
다만, Wavlelet Transform은 데이터의 공간을 바꿔버린다. (시간/공간 -> 주파수)
그리고 모든 계수를 가지고 있으면 원본을 복원할 수 있음.
Numerosity Reduction은 데이터의 표현 방식을 바꿔버린다. (개별 값 -> 통계값이나 모델 파라미터)
히스토그램이나 샘플링된 값은 원본 데이터의 개별 값을 완벽하게 복구할 수 없다.
Data Reduction 이라는 큰 틀에서는 동일하지만.. 세부적으로 들어가면 좀 다름.
지금까지는 데이터를 어떻게 줄일지에 대해서 다뤘다면, Feature Engineering은 원시 데이터를 모델이 학습하기 가장 좋은 형태로 가공하는 작업을 다룬다.
Linear Model은 모두 선형 결합으로 결과를 예측하니 Nominal 변수를 그대로 넣을 수 없다.
그러니 One Hot Encoding을 사용함. -> 각 카테고리마다 고유한 특징을 생성하고 해당 카테고리에 속하면 1 아니면 0
이러면 각 요일마다 다른 가중치를 부여할 수 있어 Nominal 한 값들에 대한 영향을 독립적으로 계산할 수 있다.
특징 함수는 저차원의 입력을 고차원의 공간으로 매핑하는 과정.
차원을 늘리면 모델 자체는 여전히 선형 결합이지만, 실제 데이터의 복잡한 곡선을 표현할 수 있다.
모델이 결과를 예측할 때는 가중치를 어떻게 다루는지가 중요하다. 가중치 끼리는 선형 결합이라는것. Feature만 선형이 아님
Polynomial Features
선형 모델의 한계를 극복하기 위해 기존 특징을 제곱하거나 세제곱해서 새로운 특징을 만든다.
요일별 모델처럼 특정 조건마다 별도의 모델을 학습시키거나 기존 특징을 변환시키는것도 가능함.
다만, 모든 변수가 다 유용한건 아니다. 너무 많은 변수는 모델을 혼란스럽게 하거나 Overfitting을 유발한다.
d개의 특징이 있을 때 완탐 돌리면 2^d 만큼 탐색해야 하니 효율적으로 처리해야 함..
Feature Selection - 중복 피쳐를 제거하고, 목표와 무관한 피쳐도 제거한다. 모든 조합을 다 볼 수 없으니 하나씩 추가하거나 제거하는 휴리스틱을 사용한다.
Feature Creation - 도메인 지식을 사용해 새로운 정보를 뽑아내거나 전에 다뤘던 여러 Transform을 활용해 데이터를 새로운 관점으로 해석한다.
'Computer Science > Data Science' 카테고리의 다른 글
| [Data Science] ETRI 휴먼이해 인공지능 논문경진대회 - 2 (0) | 2026.05.05 |
|---|---|
| [Data Science] ETRI 휴먼이해 인공지능 논문경진대회 - 1 (0) | 2026.05.04 |
| [Data Science] Statistical Data Analysis (0) | 2026.04.09 |
| [Data Science] Data Acquisition and Visualization (0) | 2026.03.28 |
| [Data Science] Decision Tree & Regularization (0) | 2026.03.14 |